 By
By
What ArchiveFlow is solving and why clear definitions come first
ArchiveFlow basic definitions are a set of shared terms that classify legacy systems and data into clear decisions, so organizations can retire, archive, or rebuild with confidence instead of moving everything by default. These definitions prevent "lift and shift" waste, reduce risk, and create a clean, governed foundation for analytics and AI.
Many organizations feel pressure to modernize quickly, but their real problem is not technology. It is the lack of a common language for deciding what to keep, what to decommission, and what to redesign. ArchiveFlow’s framework turns vague conversations about "old systems" into a structured, repeatable decision process executives can trust.
The four ArchiveFlow decision buckets and what each one really means
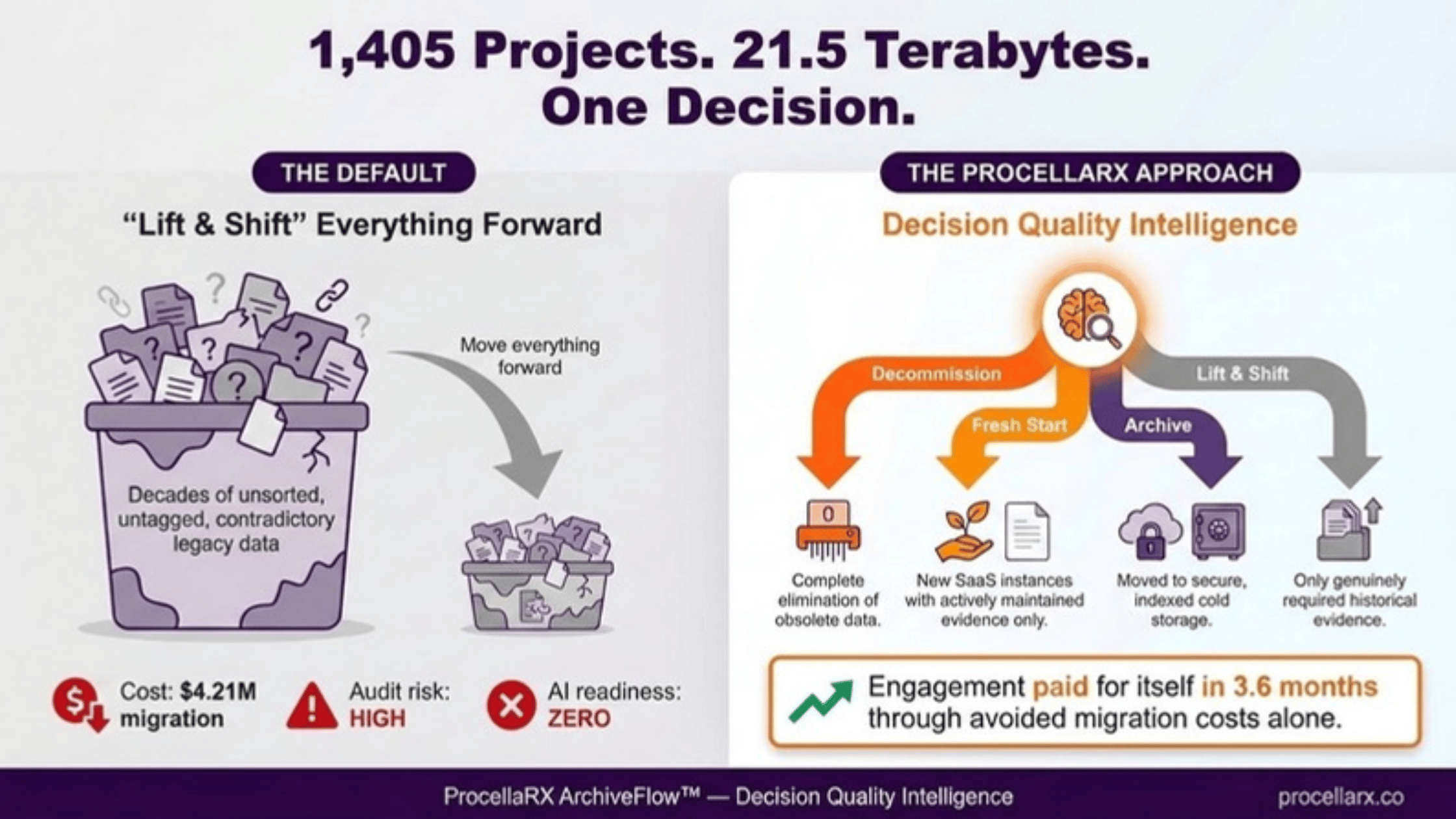
ArchiveFlow organizes every legacy application or data set into four buckets: decommission, archive, fresh start, and lift and shift. Decommission means shut down and delete, because the information has no legal, business, or scientific value. Archive means keep the data in a controlled, low-cost, read-only environment for compliance or reference.
Fresh start is used when the data is messy, inconsistent, or unsafe to reuse, so teams design a new model, migrate only what is needed, and set modern controls from day one. Lift and shift is the exception, not the default: it is reserved for cases where the existing system is already well governed, low risk, and aligned to future needs, similar to guidance in data migration literature from Datafold.
How these definitions protect modernization budgets and timelines
Without ArchiveFlow-style definitions, modernization projects quietly absorb decades of redundant, obsolete, or trivial data. Industry analyses show that most failed projects underestimate the cost of migrating poor-quality information. In one evaluation of over 1,400 projects, deleting only about 6 percent of total projects produced roughly two-thirds of annual run-rate savings.
These outcomes are only possible because decision-makers agree on what each bucket means and apply it consistently. When teams know exactly what qualifies for decommission versus archive, they can model cost, risk, and schedule more accurately. This eliminates long debates during execution and helps leaders stop funding systems and data that no longer serve any purpose.
Using ArchiveFlow basics to build an AI‑ready and compliant data foundation
Clear ArchiveFlow definitions also shape an organization’s AI readiness. AI models trained on uncontrolled legacy data can expose confidential information, amplify bias, or violate retention rules. By routing each system through the four buckets, teams remove unsafe data, isolate compliant archives, and preserve a reliable record of what was changed and why.
For regulated life sciences, this is especially important. Auditors care less about slogans and more about traceable decisions: which records were deleted, which were archived, who approved each step, and what controls exist around the data used for AI. Starting with basic definitions gives organizations a practical way to show that modernization, archiving, and AI initiatives are all governed by the same, transparent rules.

.jpg)
